Genie: Generative Interactive Environments
“What if, given a large corpus of videos from the Internet, we could not only train models capable of generating novel images or videos, but entire interactive experiences?”
Model Components
- Latent Action Model - infer action between two states
- Video Tokenizer - compress images and videos
- Inverse & Forward Dynamics Model - predict future state based on current state and action
Training happens in two stages.
Stage 1: Video Tokenizer
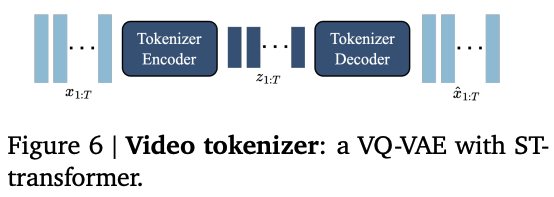 Take a set of frames, encode and decode again. VQ-VAE objective.
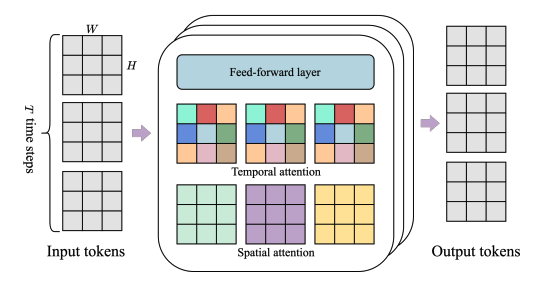
The encoder and decoder are a spatio-temporal (ST) transformer, which by default does not scale well due to attention complexity. Therefore, they use spatiotemporal blocks, with one spatial attention (per image), one temporal attention (per patch across time), and a feed-forward layer. Thus the most expensive part (spatial attention) scales linearly with number of frames.
Take a set of frames, encode and decode again. VQ-VAE objective.
The encoder and decoder are a spatio-temporal (ST) transformer, which by default does not scale well due to attention complexity. Therefore, they use spatiotemporal blocks, with one spatial attention (per image), one temporal attention (per patch across time), and a feed-forward layer. Thus the most expensive part (spatial attention) scales linearly with number of frames.
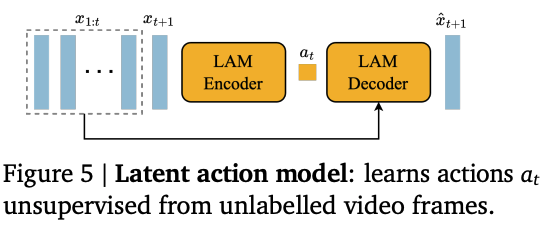
Stage 2: Latent Action & Dynamics Model
To train a latent action model, the authors encode N+1 frames, predict an action a, and decode the N+1’th frame given action a and the first N frames. Ie the encoder sees the “future state” and has to predict an action that the decoder can use to re-generate the future state. The authors find that training the LAM Encoder & Decoder on Raw Frames (instead of using the Video Tokenizer) works better (Table 2).
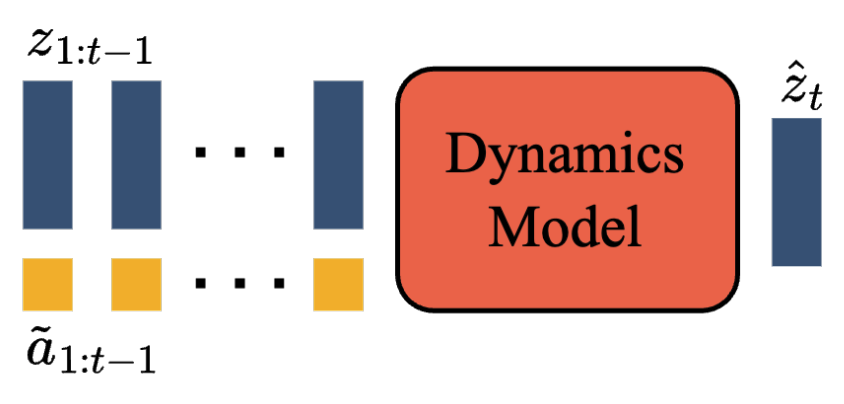
 Given the latent actions, the dynamics model is now tasked to predict future states given only the current state and an action.
Given the latent actions, the dynamics model is now tasked to predict future states given only the current state and an action.
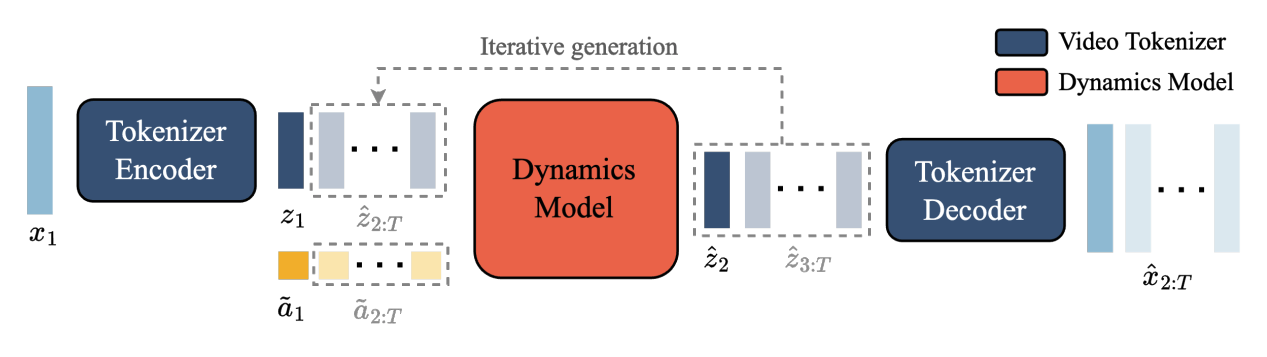
Inference
Given a current video frame and an action (user input), the dynamics model predicts the next frame (which gets decoded into pixels for the user), and waits for the next action from the user.
Thoughts
- great visualizations which make it really easy to understand the high level idea