LVSM
Goal
scalable and generalizable NVS (from sparse-view). They want to avoid/minimize 3D inductive biases:
(a) representation-level bias: using NeRF or 3DGS as an intermediate representation introduces bias not only in the structure, but also in the rendering function.
Images -> scene representation -> specific rendering model.
(b) architecture-level bias using specialized architectures like CNNs, cost volumes etc. LVSM instead just uses the transformer architecture and MLPs.
Method
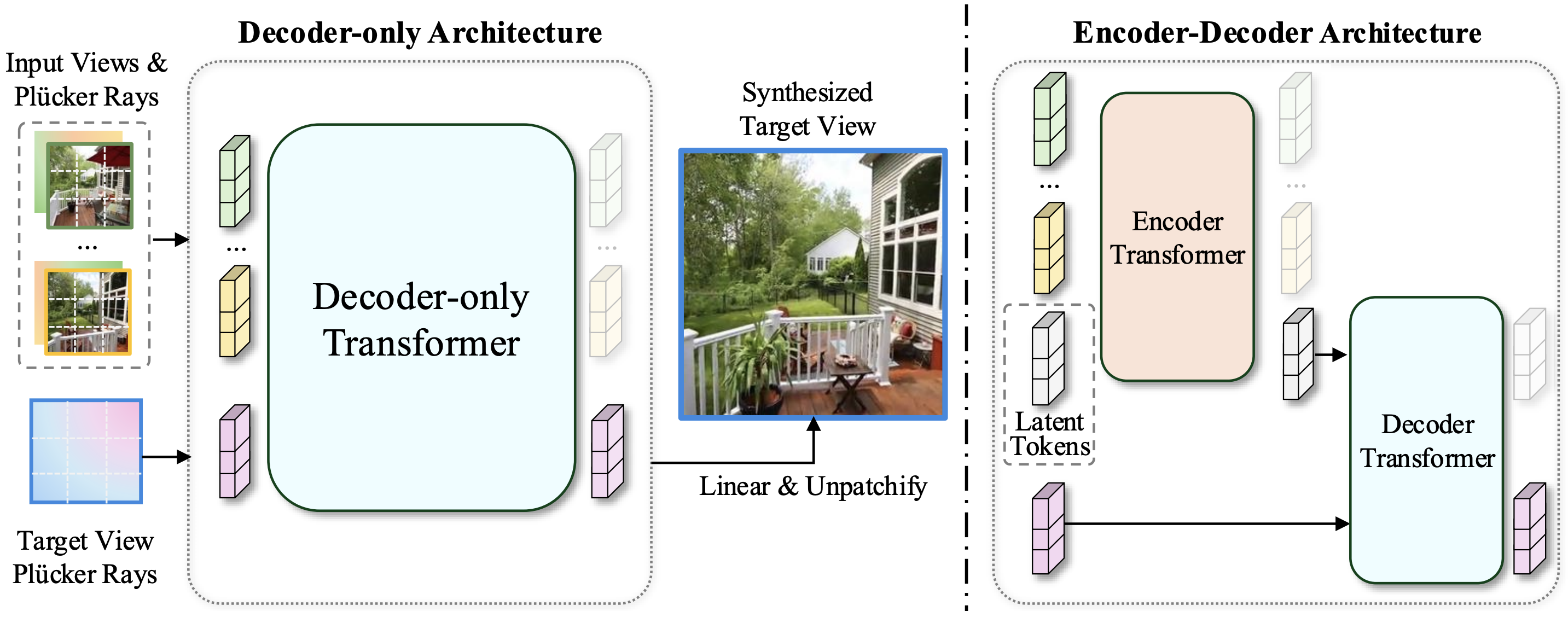
Introduce two methods, one that has a latent scene representation, and one that removes the concept of it in general:
- encoder-decoder: encoder is a reconstructor, latent tokens are the scene representation, decoder is a neural renderer \
- decoder-only: patchify images + target view plücker rays, decoder only to synthesize target view
Results
Overall, the decoder-only architecture has better quality and scales better. However, when it comes to pure rendering speed of novel views, encoder-decoder is faster as it needs to only calculate the latent scene representation once from which it can render views.
Ablation: MLP Tokenizer > CNN-based tokenizer.
Thoughts
Cool to see that even on low-gpu budget they can train competitive models.