True Self-Supervised Novel View Synthesis is Transferable
tl;dr: camera trajectory from one scene should render same trajectory in other scene.
Claim: The key criterion for determining if a model is capable of Novel View Synthesis (NVS) is transferability (of poses): given a camera trajectory extracted from one scene, it should render the same trajectory in a different scene. Current self-supervied methods like RayZer do not produce transferable poses. Authors hypothesize that these methods use latent pose to encode how to interpolate context views to synthesize target view instead.
Current Self-Supervised NVS systems consistent of 3 main components:
- : Images Poses
- : Images + Poses Scene Representation
- : Target Pose + Scene Representation Target Render
For traditional methods, , where is often chosen as COLMAP or VGGT.
To measure transferability, they introduce True Pose Similarity (TPS):
where and are sequences of images from two scenes, and is some pose distance metric, like RRA/RTA/AUC.
Applying the function to our self-supervised framework results in:
XFactor
Based on the Transferability insight above, to truly disentangle poses, authors derive Transferability Objective, rendering novel views in sequence by using pose encodings from sequence . Assume both and are split into context and target frames. Then the training objective becomes
where the scene encoding is absorbed into the renderer: . The main issue in this formulation lies in the fact that we cannot control that two image sequences have the exact same camera trajectory. Therefore, the authors propose to use pose-preserving augmentations that separate a single sequence into two non-overlapping subsequences:
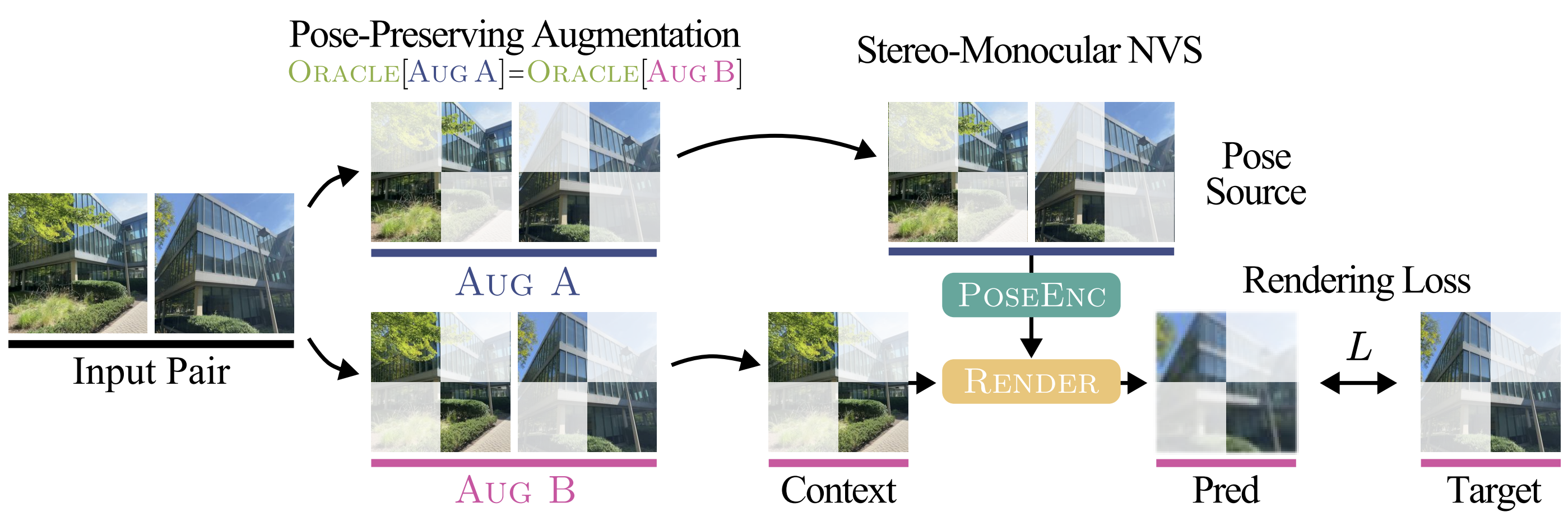
They train a stereo-monocular model (one context frame, one target frame).
Results
True Pose Similarity: XFactor >> RayZer/RUST both qualitatively and quantitatively.

Left: First compute pairwise from first to all other frames. Then render novel views providing context frame.
Right: VGGT poses of rendered images.
Pose Probe: Probing the pose shows that while XFactor outperforms RayZer/RUST, these models do still encode useful information about it (it just doesn’t show up in the TPS score).
Ablations: Adding additional view to / (to make it multi-view) degrades TPS and probed poses. Why?
What does this mean? That networks starts to try and interpolate and reuse the pose encoding for something else?
Thoughts
- TPS is only necessary because XFactor has purely latent poses - RayZer eg has explicit poses than can be used directly at inference - but for XFactor (latent variable model), controllability=transferability
- Evaluation focusses on poses, not on NVS quality (appentix still shows that its significantly better than RayZes or RUST)
- PoseEnc is always pairwise. Making it multi-view while ensuring pose latents are still well-behaved could be interesting.
- Claim: “NVS is simply the ability to render a scene from a user-controllable viewpoint: It is critical that the same camera pose always results in the same viewpoint being rendered. If the model cannot do this, it is not a true NVS model, but rather, a frame interpolator.”
- I feel like NVS can be seen as frame interpolation.
- scale ambiguity. what is the correct way to transfer poses.
- How does rendering quality behave when adding more context frames?