LagerNVS
Hypothesis & Idea:
Novel View Synthesis (NVS) has long been approached through per-scene optimization (eg NeRF, 3DGS): Images -> Encoder(Optimization) -> Render. Recently, people have started to use learned feed-forward reconstuction models: Images -> Encoder(Learned) -> Render. The next, pioneered by [LVSM], is to not only learn the scene encoding but also the rendering end-to-end. Authors explore this idea and architectural choices for it.
Method
The main architectural contribution is the following:
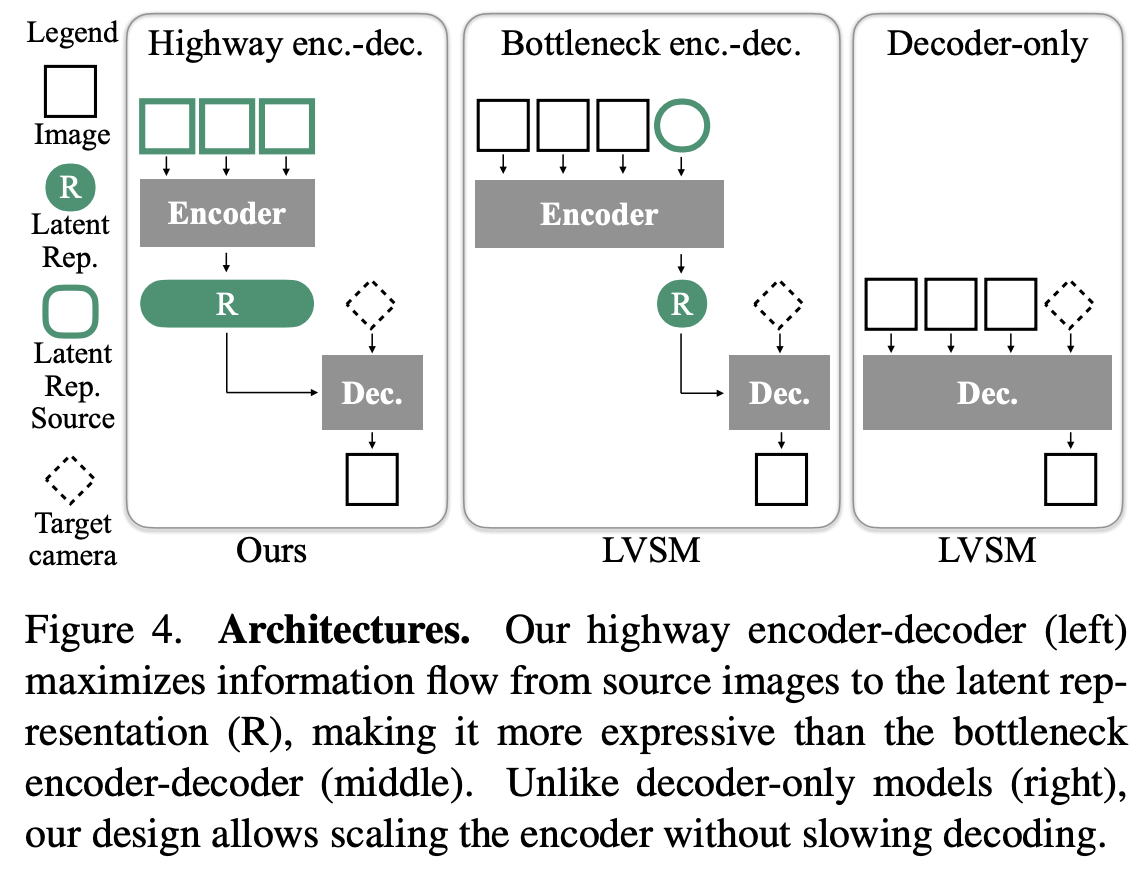 They follow the encoder-decoder paradigm. Instead of having a “bottleneck” that restricts the size of the latent representation, they use a “highway” latent representation, which size corresponds to the number of input images.
They follow the encoder-decoder paradigm. Instead of having a “bottleneck” that restricts the size of the latent representation, they use a “highway” latent representation, which size corresponds to the number of input images.
Results
- highway > bottleneck
- VGGT pretrained weights >> Dino pretrained weights > random init.
- LagerNVS >> Feed-forward 3DGS methods
Thoughts
- I think that the results that highway > bottleneck is expected as is just increases the capacity of the latent scene representation.
- The fact that VGGT pretrained weights >> Dino pretrained weights shows that some understanding of 3D is beneficial (and that VGGT has a consistent latent representation)
- Most interesting and somewhat surprising is that LagerNVS is way better than feed-forward 3DGS methods. The authors say that this is in part because the neural approach can fill simple unseen regions, which 3DGS cannot by design.